

Open AI has released a generative AI text-to-video (T2V) tool. It's called sora, and it's a generative AI that lets you type in text and generate an image of your choice.
OpenAI introduced the features, differences, and future development of sora, an AI video generator, in detail on the company's blog. Generative AI, which creates videos, images, and text based on given commands (prompts), is taking the creative world by storm.
The use of AI was a major issue in the 2023 Hollywood writers' (WGA) and actors' (SAG-AFTRA) strike. Many writers and actors are already using AI in their creative endeavors.
AI is moving beyond assisting on set to taking ownership, and with advances like Sora, video-generating AI can take charge from the beginning (script) to the end (video). In this sense, AI in 2024 is likely to change the landscape of the creator economy.

Sora is similar to AI video creation tools like Meta and Google, as well as AI video startups Runway and Pika Labs, but it takes the technology to the next level of AI representation.
Traditional generative AI-based video generators have struggled to accurately simulate complex scenes, especially when it comes to understanding cause and effect;
For example, if you order a video of a person taking a bite out of a cookie, Generative AI will create both the cookie and the person. But in reality, the cookie might not have a "bite mark" on it.
They also often confuse the spatial details of prompts, such as confusing left with right, and are unable to accurately describe events in chronological order, such as following a specific camera trajectory. Open AI says that Sora AI significantly addresses these weaknesses in video generation solutions.
오픈AI가 생성AI 텍스트 기반 비디오(text-to-video (T2V)) 툴을 내놨다. 소라(sora)라는 이름의 생성AI인데, 텍스트를 입력하면 원하는 이미지를 만들어준다. 오픈AI는 회사 블로그를 통해 AI비디오 생성기 소라의 특징과 차이점, 향후 개발 방향을 상세히 소개했다. 주어진 명령(프롬프트)에 따라 비디오, 이미지 텍스트를 만들어내는 생성AI는 창작 세계를 강타하고 있다.
2023년을 강타한 할리우드 작가(WGA)와 배우 조합(SAG-AFTRA) 파업에서도 AI사용은 협상의 주요 쟁점이었다. 이미 많은 작가나 배우들이 창작 활동에 AI를 활용하고 있다. AI는 제작 현장에서 보조를 넘어 주체를 넘보고 있다. 소라 등 비디오 생성 AI는 창작의 시작(각본)에서 끝(영상)까지 책임질 수 있다. 이런 점에서 2024년 AI는 크리에이터 이코노미 지형을 바꿔놓을 가능성이 높다.

[정확한 디테일에 복잡한 장면 제작 가능]
소라는 메타(Meta)나 구글(Google), AI비디오 스타트업 런웨이(Runway), 피카 랩스(Pika Labs) 등이 공개한 AI비디오 생성툴과 유사한 형태다. 그러나 그동안의 기술 발전을 AI재현 수준에서 한단계 업그레이드된 모습이다.
기존 생성AI 기반 비디오 제너레이터의 경우 복잡한 장면을 정확히 시뮬레이션하는 데 어려움이 있었다. 특히, 원인과 결과를 이해하지 못하는 경우가 많았다.
예를 들어 어떤 사람이 쿠키를 한 입 베어물었다는 영상 제작을 주문하면 생성AI는 쿠키와 사람을 모두 만든다. 하지만 정작, 쿠키에 ‘물린 자국’이 없을 수도 있다.
또 왼쪽과 오른쪽을 혼동하는 등 프롬프트의 공간적 세부 사항을 혼동하는 경우가 많고 특정 카메라 궤적을 따라가는 등 시간 순으로 발생하는 이벤트에 대한 정확한 설명을 하지 못한다. 오픈AI는 소라 AI가 이런 비디오 생성 솔루션들의 약점을 상당히 보완했다고 밝혔다.
오픈AI에 따르면 소라는 다양한 여러 캐릭터, 특정 유형의 움직임, 피사체와 배경의 정확한 디테일이 담긴 복잡한 신(complex scenes)을 만들어낼 수 있다.
텍스트나 이미지, 텍스트와 이미지를 함께 프롬프트로 입력해도 결과물이 나온다. 프롬프트에 따라 최대 1분 길이 동영상을 생성할 수 있다고 밝혔다. 오픈AI는 AI가 사람들에게 실제 상호작용이 필요한 문제를 해결하는 데 도움이 되는 모델을 만드는 것이 목표라고 밝혔다. 이를 위해 움직이는 물리적 세계를 이해하고 시뮬레이션하는 방법을 AI에 가르치고 있다고 언급했다.
소라는 디퓨전 모델(diffusion model)이다. 정적 노이즈 동영상으로 시작해 여러 단계에 걸쳐 노이즈를 제거해 동영상을 만들어낸다. 소라는 전체 동영상을 한 번에 생성하거나 생성된 동영상을 확장하여 더 길게 만들 수 있다. 실제, 공개된 소라는 사용자 프롬프트(명령)를 이해할 뿐만 아니라 실제 세계가 어떻게 존재하는지도 이해한다(The model understands not only what the user has asked for in the prompt, but also how those things exist in the physical world).
사용자 명령에 따르지만 완전히 세상과 동떨어지는 이미지들을 만들지는 않는다는 이야기다. 소라는 언어에 대한 깊은 이해를 바탕으로 프롬프트를 정확하게 해석하고 생동감 넘치는 감정을 표현하는 매력적인 캐릭터를 생성할 수 있다.
오픈AI는 소라에 한 번에 여러 프레임을 예측할 수 있는 기능을 탑재했다. 이를 통해 프레임 단위가 아닌 전체 비디오를 한 번에 생성할 수 있다. 피사체가 일시적으로 시야에서 사라지더라도 동일하게 유지되도록 하는 문제를 해결했다. 소라는 DALL-E 및 GPT 모델 기술을 탑재했다. 이에 텍스트뿐만 아니라 정지 이미지를 가져와서 동영상을 생성할 수 있으며, 이미지의 내용을 정확하고 세세한 부분까지 애니메이션으로 표현할 수 있다.
[AI제작이 만들 변화]
샘 알트만은 소라의 성능을 자신하며 프롬프트에 따라 다양한 이미지를 만들어내는 장면을 시연했다. 한 명이 "드론 카메라로 자전거를 타는 선수들이 다양한 동물들과 함께 바다 위를 달리는 자전거 경주"를 요청했다. 그러자 알트만은 소라가 만든 펭귄, 돌고래 등 다양한 바다 생물이 자전거를 타고 있는 영상을 공개했다.
https://t.co/qbj02M4ng8 pic.twitter.com/EvngqF2ZIX
— Sam Altman (@sama) February 15, 2024
오픈AI의 소라는 할리우드와 동영상 크리에이터 시장을 크게 흔들 것으로 보인다.
이를 활용하면 AI가 콘텐츠 기획, 제작, 편집까지 담당하는 ‘AI프로덕션(AI Production)’이 현실화될 수 있다. 사이버필름(Cyber Film)과 같이 이미 AI가 각본 초안을 쓰고 이를 다양한 장르와 스타일(작가)로 구성해주는 AI작가 솔루션 회사들이 등장하고 있다.
사이버필름은 AI를 이용해 영화제작자들이 스토리보드나 각본을 만드는 작업을 돕는다. 사이버 필름의 목적은 사람 작가나 영화 제작자를 AI로 대체하는 것이 아니다. 오히려 대량 자본 없이도 영화나 TV를 만들수 있도록 영화 제작 과정을 민주화하는 것이다.
CEO 러셀 팔머(Russell Palmer)는 2021년 사이버필름을 만들고 2023년 사이버필름의 핵심 솔루션인 사가(Saga)를 개발했다. 사가(Saga)의 첫 번째 핵심 기능은 시나리오 도우미다.
사가를 이용하면 작가들은 캐릭터 설정, 장르, 스토리 기본 구성까지 도움을 받을 수 있다. 간단한 프롬프트만 입력하고 다양한 설정을 정리하면 새로운 작품 생성이 가능하다. 이를 통해 작가들은 기본 골격 드래프트를 만들 수 있다.
공개한 샘플만 놓고 보면 오픈AI의 소라는 지금까지 나온 툴 중에 가장 인상적인 비디오 디퓨전 모델(video diffusion model)이다. 그러나 아직까지는 할리우드 제작 현장에서 쓰일 정도는 아닌 것으로 보인다.
메타피직스 CEO 이자 공동 창업주 톰 그래햄(Tom Graham)은 “소라는 실감형 콘텐츠의 방향성을 제시하는 엄청난 성과다”라며 “그러나 창작 작업에는 공연과 장면에 대한 완전한 제어를 요구하기 때문에 디퓨전 모델로 할리우드 영화를 제작하기까지는 아직 갈 길이 멀다"고 말했다.
메타피직스는 미라맥스 영화 ‘Here’에서 톰 행크스의 디에이징(de-aging)을 진행한 AI 엔터테인먼트회사다.
텍스트 프롬프트를 기반으로 새로운 짧은 동영상 생성, 2D 이미지를 기반으로 동영상 생성(예: 이미지 애니메이션), 인페인팅(새로운 시각 요소 교체 또는 삽입) 및 아웃페인팅(샷을 원래 프레임 밖으로 확장하여 맥락과 관련된 콘텐츠로 채우기) 등이 포함된다. 여기에 소라는 이전 TV2 툴과 다른 점들이 있다.
소라의 특징
- 비디오 품질과 현실성(Video quality and realism): 다른 모델의 결과물에 비해 훨씬 더 사실적이고 충실도가 높음
- 동영상 길이(Video length): 소라의 동영상 출력은 프롬프트에 일관성을 유지하면서 최대 1분 길이까지 가능. 2023년 8월 기준으로 4초에서 최대 18초까지 생성할 수 있는 런웨이의 2세대보다 훨씬 긴 길이.
- 시공간적 일관성(Spatiotemporal consistency): 생성된 동영상을 확장하여 더 길게 만들 수 있음. 이 기능의 힘은 다른 맥락에서 가장 잘 이해됨. 피사체가 일시적으로 시야에서 사라져도 동일하게 유지되도록 하는" 문제를 해결(making sure a subject stays the same even when it goes out of view temporarily)
이럴 경우 여러 개 비디오 출력을 샷(Shot) 으로 연결해 AI가 생성한 영화를 만들 수 있다. 보통 AI로 여러번 이미지를 생성할 경우 캐릭터와 장면의 연속성을 유지하기 어렵다.
동일한 프롬프트 또는 컨디셔닝 파라미터(conditioning parameters)를 사용해 이미지를 반복 생성해도 디퓨전 툴이 동일한 결과를 생성하지 못하기 때문이다. 아직은 1분 남짓의 영상을 만들지만, 향후 제작 길이와 완성도가 높아질 경우 영화나 TV 제작에서 보다 더 큰 역할을 할 것으로 예상된다.
하지만, 소라의 확장(extender) 기능은 한 출력물에서 다음 출력물까지 캐릭터나 객체의 연속성을 유지할 수 있게 한다. 이를 이용하면 보다 더 긴 AI 생성 스토리텔링을 가능하게 할 수 있다.
이런 발전에도 불구하고 할리우드 제작 현장에서 소라를 바로 쓰기에는 어렵다. 버라이어티는 성능 발전에도 할리우드 작업 현장에서 AI소라가 쓰일 수 없는 이유들을 담아 기사화했다.
할리우드에서 소라 사용이 주저될 수 밖에 없는 이유(버라이어티)
- 연속성(Continuity): 소라가 약속한 기술 개선은 아직은 영화나 TV 프로그램의 일관된 내러티브(coherent narrative)나 룩을 보장할 만큼 주제/대상/ 환경의 연속성을 완전히 담보하지는 않음. 다른 모델처럼, 소라도 다른 이미지 및 비디오 모델에서 나타나는 '물리 실패(physics fails)'로 인해 실제 세계 모습이나 행동을 가끔 잘못 해석하는 경우가 있음
- 제어가능성(Controllability): 일부에서는 비디오 생성AI툴을 카메라에 비유하기도 하지만, 동영상을 물리적으로 녹화하는 것이 아니라 렌더링하는 방식임. 때문에 소라는 영화 제작자에게 충분한 창의적 통제력과 결과물을 제공하고 조작할 수 있는 정밀성을 제공하지 못함. 이에 단기적으로는 AI가 기존 방식보다 더 어렵고 제약이 많을 수 있다는 것을 의미. 소프트웨어에 새로운 제어 매개변수가 추가되면서 조금씩 변화하고 있지만, 그렇다고 해서 AI 비디오가 카메라 영상에 비해 자동으로 크게 향상되는 것은 아님
- 저작권(Copyright): 할리우드 스튜디오들은 생성AI가 만든 콘텐츠가 저작권을 침해하지 않는다는 것을 100% 확인해야 작업에 활용할 것으로 보임. AI 지원 저작물이 저작권 보호를 받을 수 있는지 여부, 소라가 저작권이 있는 자료를 학습했을 가능성도 배제할 수 없다.
크리에이터들의 관심은 높은 편이다. 미스터 비스트(MrBeast)로 잘 알려진 유튜버 지미 도날드슨(Jimmy Donaldson)은 샘 알트만의 x에 대해 "샘은 나를 노숙자로 만들지 말라"고 농담을 건넸다. 런웨이의 CEO 크리스 발렌수엘라는 "게임 시작(game on)"이라는 짧은 글을 올렸다.
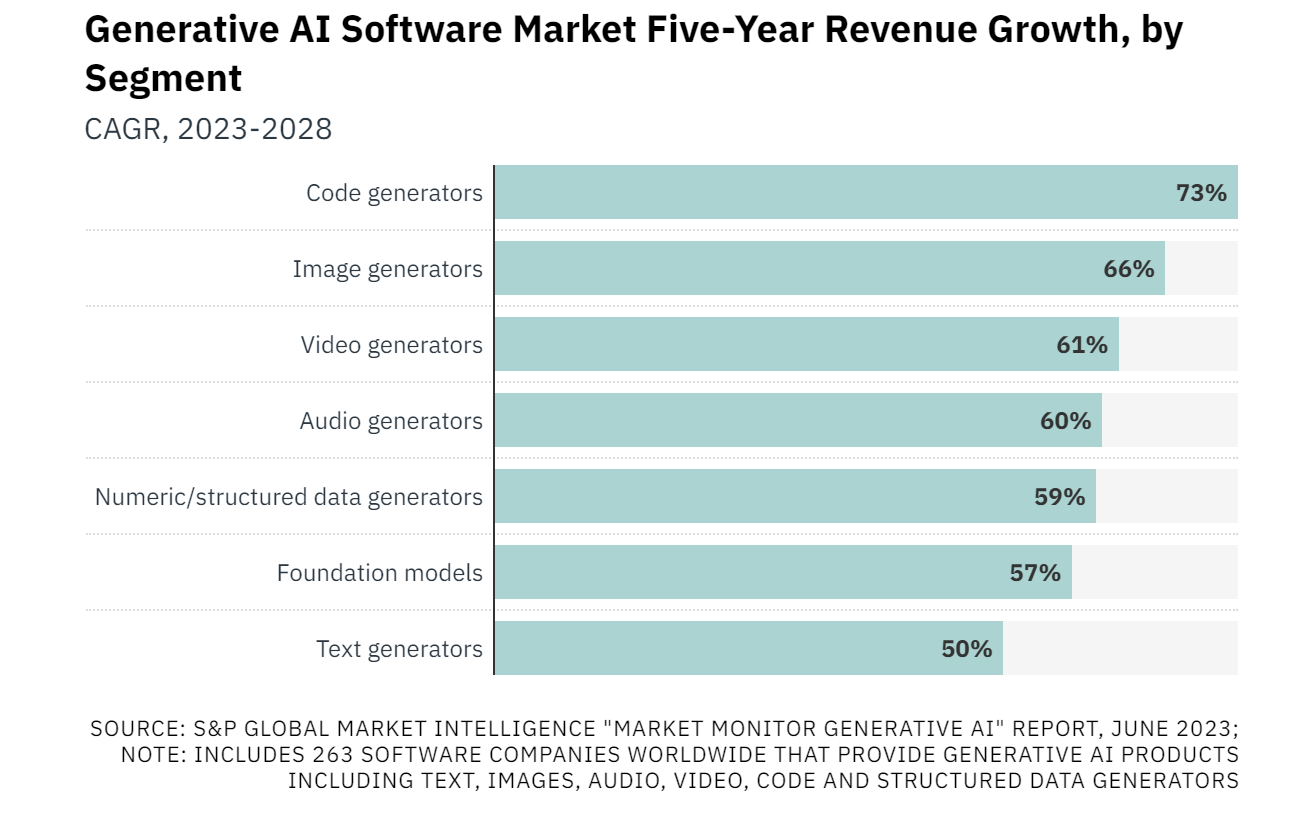
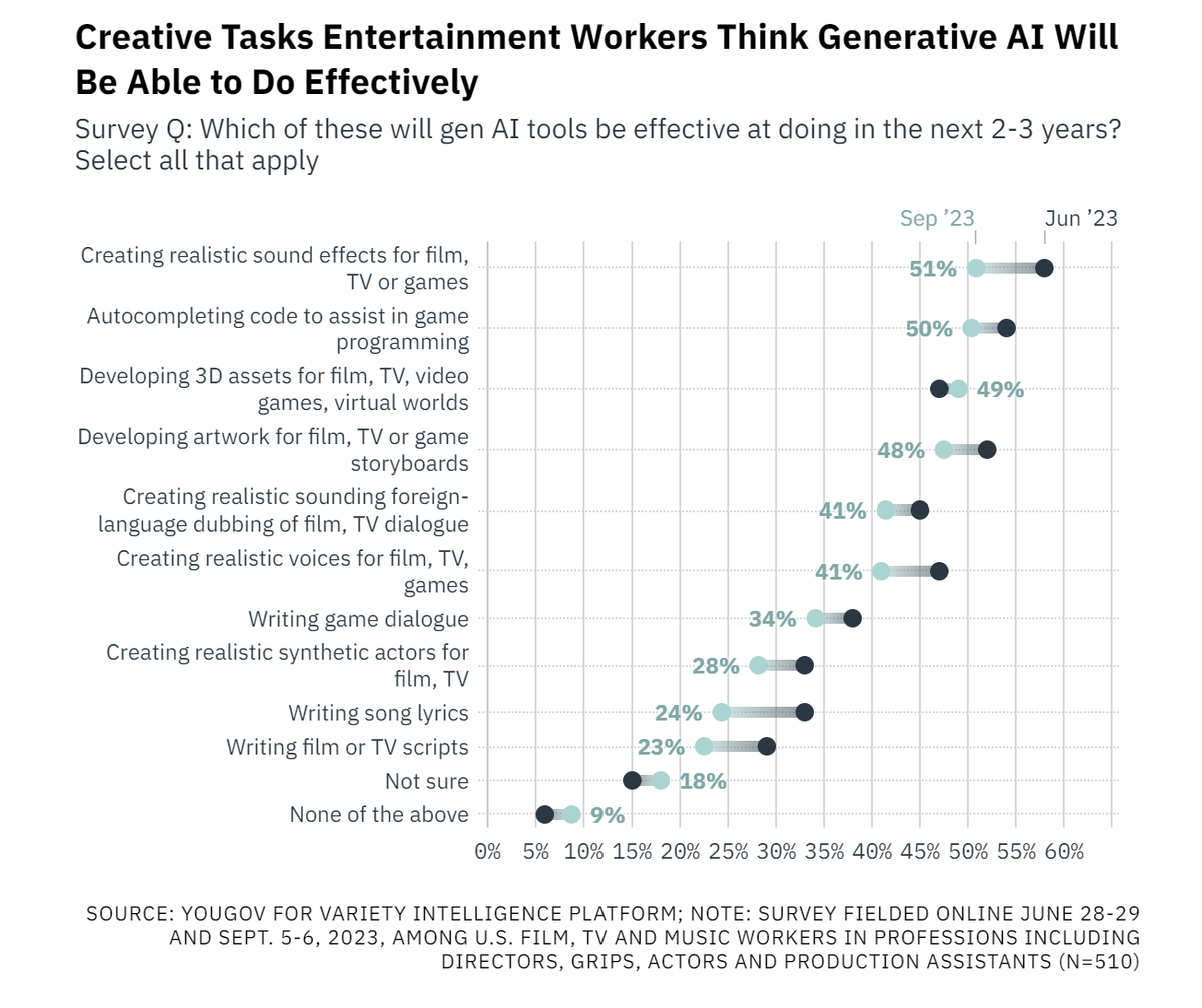
버라이어티가 2023년 6월 510명의 성인을 대상으로 물은 ‘크리에이티브 AI가 향후 2~3년 내 효과적으로 적용될 영역’에 대한 설문에 따르면 응답자의 50%가까이가 영화나 TV에서의 창작 작업이라고 답했다. 나머지 사운드, 코딩, 번역 등도 50%가 넘는 높은 수치였다.
하지만, 소라 역시 완전하지 않다.
오픈AI는 소라의 완성도를 높이기 위해 비주얼 아티스트, 디자이너, 영화 제작자 등에게 피드백을 받고 있다. 크리에이터 인더스트리를 의식하는 모습이다. 오픈AI는 소라의 안전성이 높아지기 전까지는 일반 공개는 미룰 계획이다. 잘못된 정보, 혐오 콘텐츠, 편견을 줄이기 위한 노력과 AI 생성 라벨을 붙이는 등 다양한 안전 문제를 해결하기 위해 계속 노력하고 있다. 구글 연구원들이 T2V 확산 모델인 ‘루미에르가 "가짜 또는 유해한 콘텐츠를 만드는 데 악용될 위험이 있다"며 내린 결론과 유사하다.
생성AI를 이용해 비디오 생성 AI툴의 등장은 사라가 처음이 아니다. 구글과 메타의 AI솔루션은 물론이고 런웨이의 ‘젠2(Gen-2)’와 피카(Pika) 역시 사라와 비슷한 기능을 가지고 있다.
AI가 만드는 딥페이크(Deep fake)는 문제가 되고 있다.
특히, 정치인들의 이미지를 이용한 가짜 딥페이크가 선거를 앞두고 기승을 부리고 있다. 인터내셔널 파운데이션 포 일렉토럴 시스템스(International Foundation for Electoral Systems)에 따르면 약 70여 개 국가(40억 명의 인구)가 올해 크고 작은 선거를 앞두고 있다. 오픈AI역시 선거에 AI툴을 사용하지 못하게 하는 등 대응을 하고 있다.
때문에 안전 장치들도 탑재한다, 오픈AI가 도입할 예정인 텍스트 분류기는 극단적인 폭력, 성적인 콘텐츠, 혐오 이미지, 유명인 초상, 타인의 IP를 요청하는 등 사용 정책을 위반하는 텍스트 입력 프롬프트를 확인하여 거부할 수 있다. 가이드라인을 만들기 위해 정치인과 교육자, 아티스트 등과 계속 협의 중이다.
https://t.co/uCuhUPv51N pic.twitter.com/nej4TIwgaP
— Sam Altman (@sama) February 15, 2024
일단 AI가 생성한 콘텐츠에 워터마크를 붙이는 정책은 거의 모든 빅테크 기업들이 도입하고 있다.
그러나 소라와 같이 AI기술이 더 진보하게 되면 기술로 딥페이크를 막는 정책은 한계를 보일 수 밖에 없다. 이에 텍스트 분류기에 이어 이미지 분류기 도입이 검토되고 있다.
카네기 국제문제윤리위원회의 선임 연구원 아서 홀랜드 미셸(Arthur Holland Michel)은 영상이 공개되기 전에 영상을 분석하여 노출이나 폭력 등 문제가 될 수 있는 자료를 표시하는 이미지 분류기(image classifier)를 사용하는 것은 긍정적이라고 말했다. 그러나 그는 월스트리트저널과의 인터뷰에서 "더 큰 기능을 갖춘 새로운 제품이 출시될 때마다 잠재적으로 오용하는 방법도 다양해진다"라고 말했다.
[본격적으로 열리는 AI 버추얼 프로덕션 시대]
지금도 대부분 TV와 영화 제작 방식과 워크플로 내에서 생성 AI가 쓰이고 있다. AI 기술 발전이 계속됨에 따라 AI 모델을 통해 고품질 비디오를 완전히 또는 상당 부분 렌더링(render)할 수 있게 되면서 더 큰 변화가 일어날 것으로 예상된다. 소라의 등장으로 이 작업이 보다 빨리 현실화될 것으로 전망된다.
카메라, 세트, 로케이션, 배우 등 물리적 제작 요소들의 일부분을 대체할 수 있는 가상화 또는 합성 제작(virtualized or synthetic, production) 시대가 일반화되는 것이다. 이는 소라와 같은 비디오 생성툴로 만 해결되는 것은 아니며 아바타, 버추얼 휴먼(Avatars & Virtual Humans)에 이어 사이버필름의 사가와 같은 최종 영화 제작(End-to-End AI Filmmaking) 솔루션까지 더해져야 한다.
AI를 통한 버추얼 프로덕션의 범위는 기술이 정하는 것이 아니다. 오히려 현행법과 크리에이터, 그리고 일반 오디언스들이 기술의 한계를 결정할 수 있다. 어떤 좋은 기술도 시청자나 관람객이 어색해 한다면, 실패할 수 있다. (The truth is, the scope of virtual production with AI is not defined by the technology. Rather, existing laws, creators, and audiences can determine the limits. Any good technology can fail if the viewer or audience is uncomfortable with it)
참고
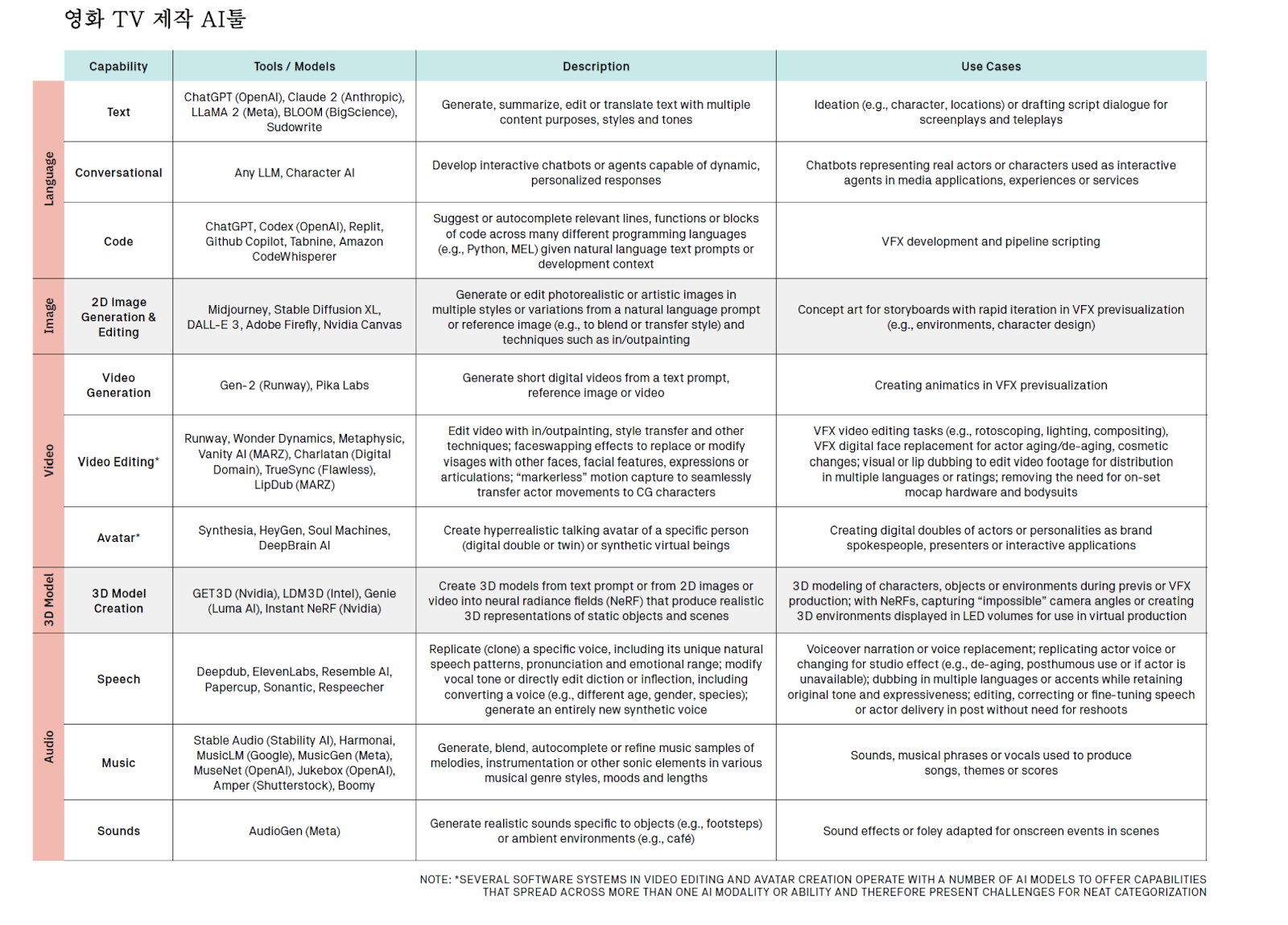
AI 비디오 생성(Video Generation) 툴 시장
대표 솔루션: 젠2(런웨이, Runway), 젠2 (Runway), 피카랩스(Pika Labs), 소라(Sora, 오픈AI)
소라, 젠2 등과 같은 텍스트 비디오 생성툴(Text-to-video (T2V))은 텍스트, 이미지, 동영상 프롬프트를 통해 소리 없이 짧은 영상(애니메이션) 출력할 수 있는 생성AI를 말한다.
구글의 멀티 모달 ‘제미니(Gemini)' 역시 비디오 생성 기능이 있다. 앞서 언급했듯이 T2V툴은 물리적으로 촬영한 비디오를 붙이는 것이 아닌 동영상을 렌더링 하는 것이다. 런웨이의 젠2는 최대 4초에서 18초까지 영상을 만들어낼 수 있다. 이에 반해 소라는 최대 1분까지 영상을 렌더링 할 수 있다고 밝혔다.
AI비디오 제너레이터의 유용한 기능은 ‘스타일 전송(Style transfer)’이다. 스타일 전송은 참조한 이미지의 특정 시각적 또는 예술적 스타일을 모든 동영상 프레임에 일관되게 적용하는 기술이다.
특정 감독이나 스타일, 이미지를 흉내낼 수 있는 것이다. 런웨이 1세대 스타일화 모드(stylization mode)는 이미지에서 가져온 클레이메이션 스타일이 실사 동영상으로 어떻게 전송되는지 보여준다.

하지만 아직은 한계가 많다. 제작 가치가 높은 영화나 프리미엄 TV 영상에 AI를 사용하기에는 너무 제한적이다. 이런 도구는 전문 아티스트가 특정 모양을 얻기 위해 결과물을 도출하거나 조작하는 데 필요한 제어 기능을 제공하기는 역부족이다. 재현성이 부족(Lack of reproducibility)하면 영상의 연속성(film continuity)에도 문제가 생길 수 있다.
그러나 앞으로 개선 가능성은 높다. 동일한 프롬프트 문구 또는 컨디셔닝 매개변수(conditioning parameters)를 사용해 반복 생성해도 동일한 결과를 생성하는 모델이 속속 나오고 있다.
버라이어티는 “비디오 생성 AI 결과물의 품질과 사실성은 계속 개선될 것으로 예상된다”며 “이는 잠재적인 유용성이 더욱 커질 것임을 보여주는 것”이라고 강조했다.
줌(Zoom), 속도 조정(speed adjustments), 카메라 회전이 가능한 런웨이 디렉터 모드(Director Mode)와 같이 사용자가 동영상 렌더링 방식을 보다 구체적으로 변경할 수 있는 새로운 제어 매개변수도 소프트웨어에 추가되고 있다.
[오픈AI의 기업 가치 103조 원]
한편, T2V까지 내놓은 오픈AI의 기업 가치는 계속 높아지고 있다. 뉴욕타임스는 투자 평가 거래에서 오픈AI의 기업 가치가 800억 달러(106조 원)에 달한다고 보도했다. 10개월이 안된 사이 기업 가치가 3개 이상 뛰어 오른 것이다. 데이터 추적업체 CB Insights에 따르면 현재 오픈AI는 바이트댄스(ByteDance)와 스페이스(Space)X에 이어 세계에서 가장 가치 있는 기술 스타트업 중 하나가 됐다.
이 회사는 벤처 기업 Thrive Capital이 주도하는 공개 매수(tender offer)를 통해 기존 주식을 매각 할 것으로 알려졌다. 이를 통해 직원들은 사업 운영을 위한 자금을 조달하는 기존 펀딩 라운드 대신 회사 주식을 현금화할 수 있다.
이 투자 거래는 오픈AI에게 결정적인 시기에 이뤄졌다. 2023년 11월 오픈AI 이사회는 리더십에 대한 신뢰가 사려졌다는 이유로 샘 알트만을 해고했다. 그러나 그의 해고는 회사에 큰 분란을 불러오고 직원들이 집단 이탈하려는 움직임을 보이자, 알트만은 다시 복귀했다. 그 사이 일부 이사회 멤버는 사임했다. 오픈AI는 지난해 혼란을 해결하기 위해, 로펌 윌머헤일(WilmerHale)을 고용해 이사회의 조치와 알트먼의 리더십을 검토했다. 윌머헤일은 2024년 초 이 사건에 대한 보고서를 완성할 예정이다.
지난 2023년 초 오픈AI는 비슷한 거래에 합의한 바 있다. 벤처 캐피털 Thrive Capital, Sequoia Capital, Andreessen Horowitz, K2 Global 등은 공개 매수를 통해 오픈AI의 주식을 약 290억 달러에 인수하기로 합의했다. 2023년 1월 마이크로소프트는 오픈AI에 100억 달러를 투자했다. 오픈AI가 지금까지 받는 투자액은 130억 정도다.





![[프리미엄 리포트] 미국 케이블TV 2025, 변화와 미래 전략](https://storage.googleapis.com/cdn.media.bluedot.so/bluedot.directmedialab/2025/05/vj931j_202505270106.png)







